
【2026年最新】ChatGPTに社内データを学習させる5つの方法|RAG・ファインチューニング徹底比較

AI組織変革事業に従事。「最後までやり切る力は誰にも負けません」をモットーに、AI導入プロジェクトの推進と組織内のチームビルディングを支援する。

社内マニュアルや顧客データをChatGPTに活用させたいのに、「どの方法が自社に合うのか」「機密情報の漏洩は大丈夫なのか」と判断に迷っていませんか。
この記事を読めば、ChatGPT 社内データ 学習の5つの手法と、2026年最新のセキュリティ対策、成功企業の導入事例がひと目でわかります。 自社の目的と予算にぴったり合う安全な導入ルートを、今日のうちに描き切りましょう。
目次
- ChatGPTに社内データを学習させるとは?2026年に企業が取り組むべき3つの理由
- ChatGPTに社内データを学習させる5つの方法【比較一覧表付き】
- ChatGPT×社内データ学習の本丸「RAG」完全ガイド【2026年最新】
- ChatGPTのファインチューニングで社内データを学習させる方法と注意点
- ChatGPTに社内データを学習させる際のセキュリティリスクと6つの対策
- ChatGPTに社内データを学習させた企業の導入事例7選【2026年版】
- ChatGPTの社内データ学習、自社に最適な方法の選び方【5つの判断軸】
- ChatGPTで社内データ学習を成功させる6つの導入ステップ
- 【2026年最新】ChatGPT社内データ活用の最新トレンドと今後の展望
- ChatGPTの社内データ学習なら株式会社デジタルゴリラへ
- ChatGPTの社内データ学習に関するよくある7つの質問【2026年最新版】
- まとめ:ChatGPTに社内データを学習させて、2026年の業務変革を加速させよう
ChatGPTに社内データを学習させるとは?2026年に企業が取り組むべき3つの理由

ChatGPTを業務に取り入れる企業が増える一方で、「結局のところ、自社の情報を読ませるにはどうすればいいのか」という壁にぶつかるケースが後を絶ちません。汎用モデルが賢くなっても、社内固有のルールや製品仕様までは知らない――この当たり前の事実こそが、データ活用に踏み込むかどうかの分岐点です。2026年の今、企業が社内データ連携を本気で検討すべき理由を、次の3つの観点から整理します。
- GPT-5.3世代でも「自社情報」は標準では答えられない
- 社内データ活用で業務効率化・属人化解消・ナレッジ継承が一気に進む
- 「学習」と「参照(RAG)」の違い──正しい理解が導入成功の第一歩
導入判断を誤らないために、まずは前提となるこの3点をしっかり押さえておきましょう。
1. GPT-5.3世代でも「自社情報」は標準では答えられない
「最新のChatGPTなら、聞けば何でも答えてくれるのでは?」――そんな期待を抱いて社内のFAQ業務に投入してみたら、的外れな一般論しか返ってこなかった。こうした「がっかり体験」は、生成AI導入初期のあるあるです。
2026年現在、OpenAIの最新モデル群(GPT-5.3 / 5.4 / 5.5系)は、推論力・文脈理解ともに前世代から大きく進化しています。とはいえ、社内特有の業務ルールや自社製品の仕様は、標準状態のChatGPTには一切含まれていません。学習データには公開情報しか入っていない以上、これは性能の問題ではなく、原理的な限界です。
自社業務に直結した正確な回答を得るには、社内データをAIと連携させる仕組みづくりが欠かせません。
2. 社内データ活用で業務効率化・属人化解消・ナレッジ継承が一気に進む
「あの案件の経緯、Aさんしか知らないんだよね」「マニュアル探すだけで30分かかった」――どの会社にもある光景です。社内データをAIに繋ぎ込むと、こうした「暗黙知の壁」と「検索コスト」の両方が一気に崩れていきます。
社内データをAIと連携させる最大のメリットは、圧倒的な業務効率化と属人化の解消です。AIがナレッジを瞬時に引き出す環境が整えば、情報を「探す時間」そのものが消え、ベテランの判断軸を新人が即座に参照できるようになります。
結果として、経験の浅い社員でもベテランと同等の質で業務を遂行できるようになり、組織全体の生産性が劇的に向上します。
3. 「学習」と「参照(RAG)」の違い──正しい理解が導入成功の第一歩
「AIに自社データを覚えさせたい」という相談を受けたとき、実は半分以上のケースで本当に必要なのは「覚えさせる」ことではなく「その都度参照させる」ことだった、という話があります。両者を混同したまま導入を進めると、不要なコストと工数を抱え込むことになりかねません。
AIに自社データを活用させる方法は、大きく「学習」と「参照」の2種類に分かれます。
一般に「AIにデータを学習させる」と呼ばれるのは、モデル内部の知識そのものを書き換える「ファインチューニング」を指すケースが多く、この手法は多大なコストと更新の手間が発生します。
もう一方が「参照(RAG:検索拡張生成)」で、外部データベースから情報を検索し、その結果を基にAIに回答を作らせる技術です。RAGはモデルを再学習させず、自社データを検索してその場で読み込ませる仕組み。目的と予算に応じて2つの違いを正しく使い分けることが、導入成功の鍵を握ります。
ChatGPTに社内データを学習させる5つの方法【比較一覧表付き】
ひとくちに「ChatGPTに社内データを使わせる」と言っても、その実現手段はノーコードで5分で試せるものから、エンジニアチームが数ヶ月かけて構築する本格システムまで幅広く存在します。重要なのは「どれが最強か」ではなく「自社のフェーズと目的に何が噛み合うか」を見極めること。本セクションで取り上げる5つの選択肢は以下のとおりです。
- プロンプトエンジニアリング(最も手軽・ノーコード)
- GPTs(カスタムGPT)でのファイル読み込み
- RAG(検索拡張生成):社内ナレッジを参照させる本命手法
- ファインチューニング:モデル自体を自社仕様にチューニング
- エンベディング(ベクトル化):大量データの類似検索に最適
各手法の特徴を順に比較します。
1. プロンプトエンジニアリング(最も手軽・ノーコード)
プロンプトエンジニアリングは、ChatGPTへの指示文(プロンプト)に直接テキストデータを貼り付けて回答を引き出す手法です。
「以下の会議メモを要約してください」と指示し、続けて社内のメモを貼り付けるだけ。特別な開発環境や追加コストは一切不要で、誰でもすぐに試せる手軽さが最大の魅力です。
ただし、一度のチャットで入力できる文字数(トークン数)には上限があるため、数百ページの社内規程や数年分の顧客対応履歴を読ませる用途には向きません。
2. GPTs(カスタムGPT)でのファイル読み込み
有料プランのChatGPT Plusなどで使える「GPTs(カスタムGPT)」機能を活用すれば、プログラミング知識がなくても独自AIアシスタントを作成できます。
PDF・Excel・Wordなどの社内ファイルを画面からアップロードするだけで、AIが内容を参照して回答する仕組みです。
部門ごとの業務マニュアルや製品仕様書など、数十〜数百ファイル規模のデータを扱うケースで大きな威力を発揮します。
3. RAG(検索拡張生成):社内ナレッジを参照させる本命手法
本格的な業務改革を目指す企業の多くが採用している本命手法が「RAG(検索拡張生成)」です。
RAGは社内のファイルサーバーやデータベースにあるドキュメントを専用システムに格納し、ユーザーの質問に関連する箇所だけを瞬時に検索してChatGPTに渡し、回答を生成させる仕組みです。
再学習が不要なため、情報が更新された際も元のファイルを差し替えるだけで最新情報を反映できます。情報元(出典)を提示できるため、AIが嘘を作る「ハルシネーション(AIが事実に基づかない情報を生成すること)」を強力に抑制できる点も高く評価されています。
4. ファインチューニング:モデル自体を自社仕様にチューニング
ファインチューニングは、既存のAIモデルに独自データを大量に読み込ませ、モデルの思考回路や出力スタイルを再調整する高度な手法です。
自社ブランド独自のトーン&マナーに合わせた文章生成や、社内独自のプログラミング言語のコード出力などに威力を発揮します。
一度学習した情報の修正には再学習が必要となるため、日々更新される社内規程を参照させる用途には向きません。
5. エンベディング(ベクトル化):大量データの類似検索に最適
エンベディングは、テキストや画像などのデータをAIが処理しやすい数値の配列(ベクトル)に変換する技術です。
「PCが立ち上がらない」という質問に対し、「パソコンが起動しない」という表現のマニュアルを瞬時に見つけ出せるのが特長。RAGシステムの中核を担う検索エンジンとして機能します。
社内に散在する膨大なナレッジから必要な情報を正確に拾い上げるために欠かせない技術です。
【早見表】5つの手法をコスト・精度・実力度・セキュリティで比較
ここまで解説した5つの手法を、導入検討の重要軸となる「コスト」「精度」「実力度(実業務への適用性や実装のしやすさ)」「セキュリティ」の4つで比較した早見表です。自社の状況と照らし合わせ、最適なアプローチを検討する際の参考にしてください。
| 手法 | コスト | 精度 | 実力度(実用性・実装難易度) | セキュリティ |
|---|---|---|---|---|
| 1. プロンプトエンジニアリング | ◎ 無料〜月額数千円程度で最も手軽 | △ プロンプトの工夫や入力できるデータ量に大きく依存する | △ 少量のデータ処理には向くが、全社的な大規模運用には不向き | △ 入力データが学習されないよう設定(オプトアウト)に注意が必要 |
| 2. GPTs(カスタムGPT) | ◯ ChatGPT Plus等の安価なライセンス費用 | ◯ アップロードした数十〜数百のファイル内容に基づき正確に回答 | ◯ ノーコードで構築でき、部門単位・チーム単位の業務に最適 | ◯ 法人向けプランを利用すればデータの二次利用を防ぐことが可能 |
| 3. RAG(検索拡張生成) | △〜◯ SaaS利用から独自開発まで予算に応じて変動 | ◎ 外部検索によりハルシネーション(嘘)を強力に抑制し最新情報を反映 | ◎ 大規模な社内データと連携でき、現在の企業AI導入における本命 | ◎ アクセス権限の制御や自社専用の閉域網(オフライン環境)での構築が可能 |
| 4. ファインチューニング | × 大量のデータ準備と高額な開発・計算コストが必要 | ◎ 自社特有の専門用語や独自の出力スタイルを模倣させる点で最高精度 | ◯ 実装難易度は極めて高いが、特定の専門タスクにおいて絶大な効果を発揮 | ◎ 作成されたカスタムモデルは自社アカウント内で専有され、外部に漏れない |
| 5. エンベディング(ベクトル化) | △ ベクトルデータベースの構築・維持に一定の費用が発生 | ◯ ]文脈や意味合いを捉えた類似検索が可能になり、検索精度が飛躍的に向上 | ◯ RAGシステムの中核を担う検索エンジンとして、本格的な運用に必須 | ◎ データは数値の配列に変換・暗号化されるため、適切に管理すれば極めて安全 |
5つの手法は、目的によって一長一短があります。プロンプトエンジニアリングやカスタムGPTは低コストかつノーコードで導入できる手軽さが魅力ですが、扱えるデータ量に制限があります。一方、RAGやファインチューニングは初期開発コストや専門知識が必要なものの、全社レベルでのデータ活用や高度な業務自動化を実現できます。セキュリティ面では、いずれの手法でも入力データがAIの学習に二次利用されない法人向けプランやセキュアなAPI環境の利用が前提条件となります。
ChatGPT×社内データ学習の本丸「RAG」完全ガイド【2026年最新】
社内データ活用の手法を比較すると、最終的にRAGを選ぶ企業が圧倒的多数派――というのが2026年の現状です。なぜここまで支持されるのか、何ができて何ができないのか、自社で構築するなら何が必要なのか。導入判断と要件定義に必要な観点を、ひとつずつ解きほぐしていきます。本セクションで扱うのは次の5点です。
- RAG(Retrieval-Augmented Generation)の仕組みを図解
- RAGが選ばれる3つのメリット
- RAG導入に必要な4要素
- RAG構築の5ステップと、よくある失敗パターン
- 自社開発 vs RAGサービス活用、どちらを選ぶべきか?
仕組みの理解からベンダー選定の考え方まで、RAGの全体像を一気通貫で押さえましょう。
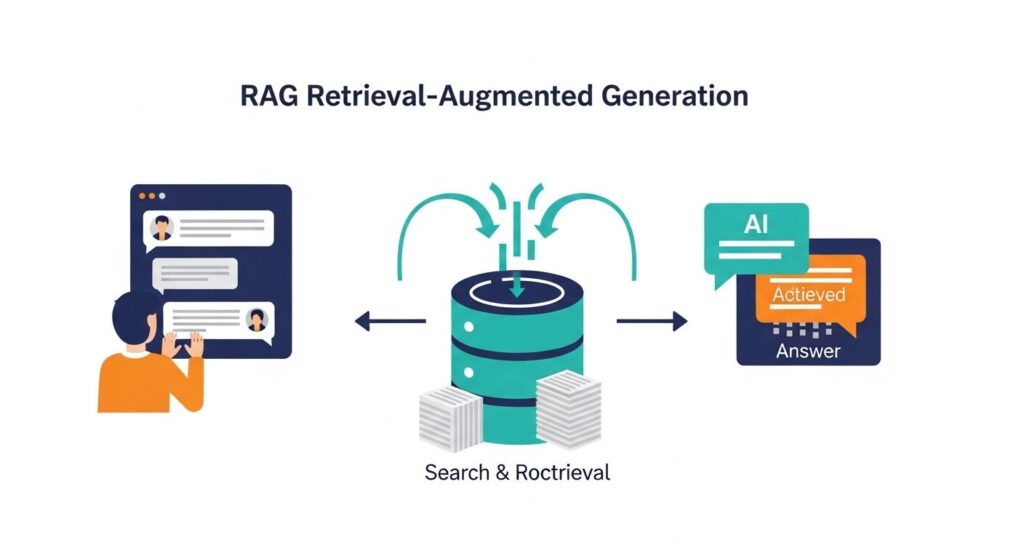
1. RAG(Retrieval-Augmented Generation)の仕組みを図解
RAG(Retrieval-Augmented Generation:検索拡張生成)の仕組みは、大きく「検索」と「生成」の2ステップで構成されます。
ユーザーが質問を入力すると、システムは社内のデータベースやファイルサーバーから関連性の高い文書を検索・抽出します。抽出された文書データとユーザーの質問をセットにしてChatGPTに渡し、回答を組み立てさせる流れです。
AIは事前に学習した世界中の知識ではなく、手渡された社内データのみを情報源として文章を組み立てるため、社内特有の専門知識にも的確に対応できる画期的な仕組みになっています。
2. RAGが選ばれる3つのメリット(ハルシネーション抑制・最新情報反映・セキュア)
RAGが多くの企業で採用される理由は、大きく3つあります。
第一に「ハルシネーション(AIがもっともらしい嘘をつく現象)」を強力に抑制できる点。RAGは必ず検索した社内データを根拠に回答を作るため、不確かな情報の混入を防げます。
第二に、情報の最新性を常に保てる点。ファイルを更新すれば検索結果も自動で切り替わり、AIを再学習させる手間とコストがかかりません。第三に高度なセキュリティで、アクセス権限を細かく制御できるため「役員向け文書は一般社員の検索結果に含めない」といった社内の閲覧権限を維持したままAI活用できます。
3. RAG導入に必要な4要素(データソース/ベクトルDB/LLM/検索ロジック)
RAGを構築するには、主に4つの技術要素が必要です。
まず、AIに読み込ませる対象となる「データソース(社内規程・マニュアル・過去の提案書などのファイル群)」。次に、それらをAIが検索しやすい数値データ(ベクトル)に変換して格納する「ベクトルDB(ベクトルデータベース)」が求められます。
検索結果を基に自然な日本語で答えを組み立てる「LLM(ChatGPTやClaudeなどの大規模言語モデル)」も不可欠です。最後に、ユーザーの質問から意図を汲み取り、データベースから精度の高い情報を拾い上げる「検索ロジック(LangChain等のフレームワーク)」を組み合わせることで、実用的なRAGシステムが完成します。
4. RAG構築の5ステップと、よくある失敗パターン
RAG構築は、①目的と対象業務の検討、②社内データの整理とデータクレンジング(不要な情報を取り除く整理作業)、③データベース構築と高速化、④LLMとの連携プロンプト開発、⑤テスト運用と精度チューニング、の5ステップで進めます。
よくある失敗パターンが、古い情報や表記ゆれのあるマニュアル、画像として貼り付けられた文字をそのままシステムに放り込んでしまうケースです。AIが正しい情報を検索できず、的外れな回答をしてしまいます。
RAGの回答精度は「読み込ませるデータの質」に直結するため、AIが読みやすいテキスト形式にデータを構造化する泥臭い作業が成功の絶対条件となります。
5. 自社開発 vs RAGサービス活用、どちらを選ぶべきか?
RAGシステムを導入する際は、自社でゼロから開発(フルスクラッチ)するか、既存の法人向けRAGサービス(SaaS)を活用するかの選択を迫られます。
自社開発は既存システムとの深い連携や独自設計の自由度が魅力ですが、エンジニアの確保や初期費用として数百万円以上のコストがかかる傾向があります。一方、市販のRAGサービスなら初期費用十万円・月額数万円程度から手軽に導入でき、数週間で社内運用を開始できるスピード感が強みです。
自社のAI活用フェーズや予算規模に応じて、適切な選択をしましょう。
ChatGPTのファインチューニングで社内データを学習させる方法と注意点
RAGが「正確な検索」を担うのに対し、ファインチューニングは「AIの振る舞いそのものを変える」アプローチです。自社ブランドの語り口、独自の出力フォーマット、業界固有の専門用語――こうした「色」をAIに染み込ませたいときに、初めて選択肢に挙がる手法と言えます。本セクションでは、向き不向きの判断軸から最新モデルでの対応状況、実装の流れまでを整理します。扱うのは以下の5点です。それぞれ詳しく解説していきます。
- ファインチューニングとは?RAGとの根本的な違い
- ファインチューニングが向いているケース・向いていないケース
- GPT-5.3 / 5.4 / 5.5系モデルでのファインチューニング対応状況と料金
- 実装ステップ(JSONLデータ作成→API呼び出し→評価)
- RAGとファインチューニングのハイブリッド活用という選択肢
1. ファインチューニングとは?RAGとの根本的な違い
ファインチューニングは、既存の学習済みAIモデルに自社が用意したデータセットで「追加学習」を行い、モデルの重み(内部パラメータ)そのものを更新する手法です。
RAGが事実関係の正確な検索に優れているのに対し、ファインチューニングはAIの「行動」や「思考パターン」を変えたい場合に力を発揮します。
特定の出力フォーマットを模倣させたり、独自の専門用語を使った自然な会話を習得させたりしたいときに選ばれるアプローチです。
2. ファインチューニングが向いているケース・向いていないケース
ファインチューニングが向いているのは、自社ブランドのトーンに合わせたキャッチコピー生成、特殊な社内プログラミング言語のコード記述、特定フォーマットに厳密に従った報告書作成など、AIの「出力スタイル」を固定化したい場面です。
一方で向かないのが、頻繁に更新される情報を扱うケース。ファインチューニングしたモデルは学習時点の知識しか持たないため、情報が変わるたびに再学習のコストが発生してしまいます。
社内規程のように更新頻度が高いデータは、RAGで扱うのが得策です。
3. GPT-5.3 / 5.4 / 5.5系モデルでのファインチューニング対応状況と料金
ファインチューニングを検討するうえで気になるのが「最新モデルでも使えるのか」「どれくらいコストがかかるのか」という現実的な部分です。2026年現在の対応状況と料金体系を整理しておきましょう。
2026年4月時点で、OpenAIのファインチューニング対応モデルはGPT-5.3を中心に、上位の「GPT-5.4」「GPT-5.5」へと拡大しています。なお、ChatGPT上ではGPT-4o・GPT-4.1・o4-miniなどの旧世代モデルが2026年2月13日に引退済みですが、API経由ではこれらのレガシーモデルも引き続き利用可能です(既存の運用を保つための措置)。
GPT-5系モデルでは、SFT(教師あり微調整)とDPO(直接選好最適化)の両手法に対応しており、従来モデルより格段に高い論理的推論能力を持つAIを独自カスタマイズ可能です。
料金は学習に使うテキストデータ量(トークン数)に応じた従量課金で、ベースモデルのAPI利用料に加え、学習時とカスタムモデル利用時の推論コストが発生します。いきなり最上位モデルに学習させるのではなく、まずはminiクラスのモデルで挙動を検証してから本番モデルへ移行する進め方が、コスト面でも品質面でも合理的です。
※参照元:OpenAI公式ドキュメント「モデルの最適化」
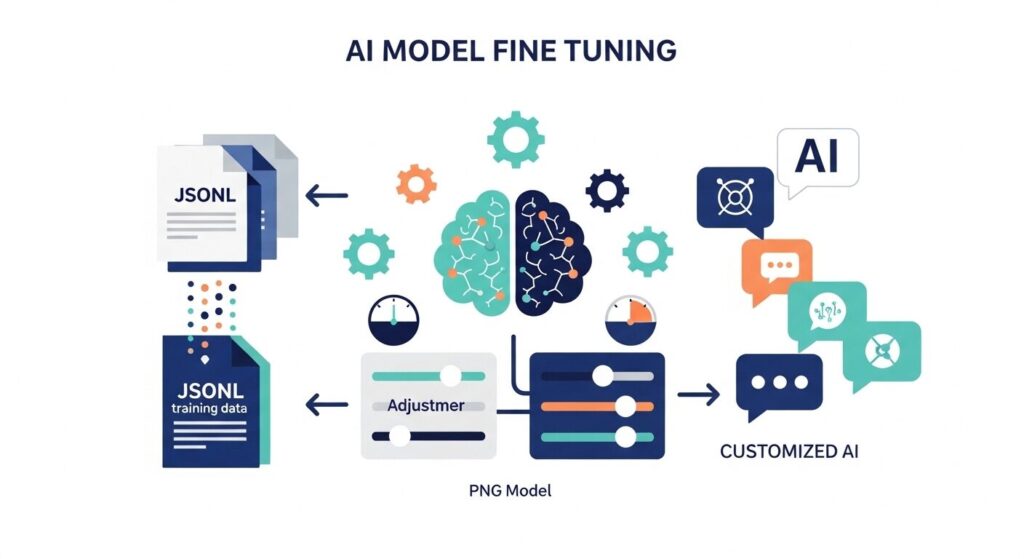
4. 実装ステップ(JSONLデータ作成→API呼び出し→評価)
ファインチューニングの基本的な実装ステップは以下の流れです。
最も重要なのが、AIに学ばせたい「ユーザーの質問(プロンプト)」と「理想的な回答」のペアを大量に作成し、JSONL形式のデータセットとして用意する作業。最低でも数十〜数百件の高品質なデータが求められます。
データが揃ったらOpenAIのAPIにアップロードし、学習ジョブを実行。完了するとカスタムモデルが生成されるため、実際にシステムへ組み込んで回答精度や出力スタイルをテストします。期待した結果が得られなければ学習データの質を見直し、チューニングを回すサイクルに入ります。
5. RAGとファインチューニングのハイブリッド活用という選択肢
近年、高度な業務自動化を求める企業で急増しているのが、RAGとファインチューニングを組み合わせた「ハイブリッド活用」です。
情報の正確性と最新性はRAGで担保しつつ、出力スタイルや業界用語の扱いはファインチューニングで最適化する使い分けを採用しています。
RAGの弱点である「出力のブレ」を抑えながら、ファインチューニングの弱点である「情報の陳腐化」も防げるため、精度が高く実務に直結する強力なAIシステムを構築できます。
ChatGPTに社内データを学習させる際のセキュリティリスクと6つの対策
AI活用で最後にブレーキをかけるのは、決まって「セキュリティは大丈夫なのか?」という一言です。ここで踏み込めずにPoC止まりになる企業と、ガバナンスを設計しきって全社展開する企業との差は、技術力ではなく「備えの精度」にあります。本セクションでは、リスクの実態から具体的な対策プラン、運用ルールの作り込みまで、全社展開に耐えうる6つの観点を整理しました。
「やってはいけないこと」だけでなく「どこまでやれば安全と言えるか」までを、順に押さえていきましょう。
1. 入力データがOpenAIの学習に使われる?リスクの正体
企業がChatGPTを利用する際、最も警戒すべきは「機密情報の漏洩」リスクです。
従業員がAIに入力した自社の顧客情報や未公開の製品データが、OpenAIのAIモデルの性能向上(再学習)のために使われてしまう可能性があります。 最悪の場合、他社ユーザーがChatGPTを使った際に、自社の機密情報が回答の一部として出力されてしまう危険性も否定できません。
防ぐためには、入力データをAIの学習に利用させない「オプトアウト(データ利用の拒否)」の仕組みを正しく適用する環境整備が、セキュリティ担当者にとって不可欠です。
2. 個人版ChatGPTのオプトアウト設定手順【画像付き解説】
無料版や個人向け有料版(ChatGPT Plus)を業務で使う場合、デフォルト(初期設定)では入力データが学習に利用される設定になっています。
設定画面から「データコントロール」→「すべての人のためにモデルを改善する」をオフにすることで、入力データがモデル学習に使われなくなります。
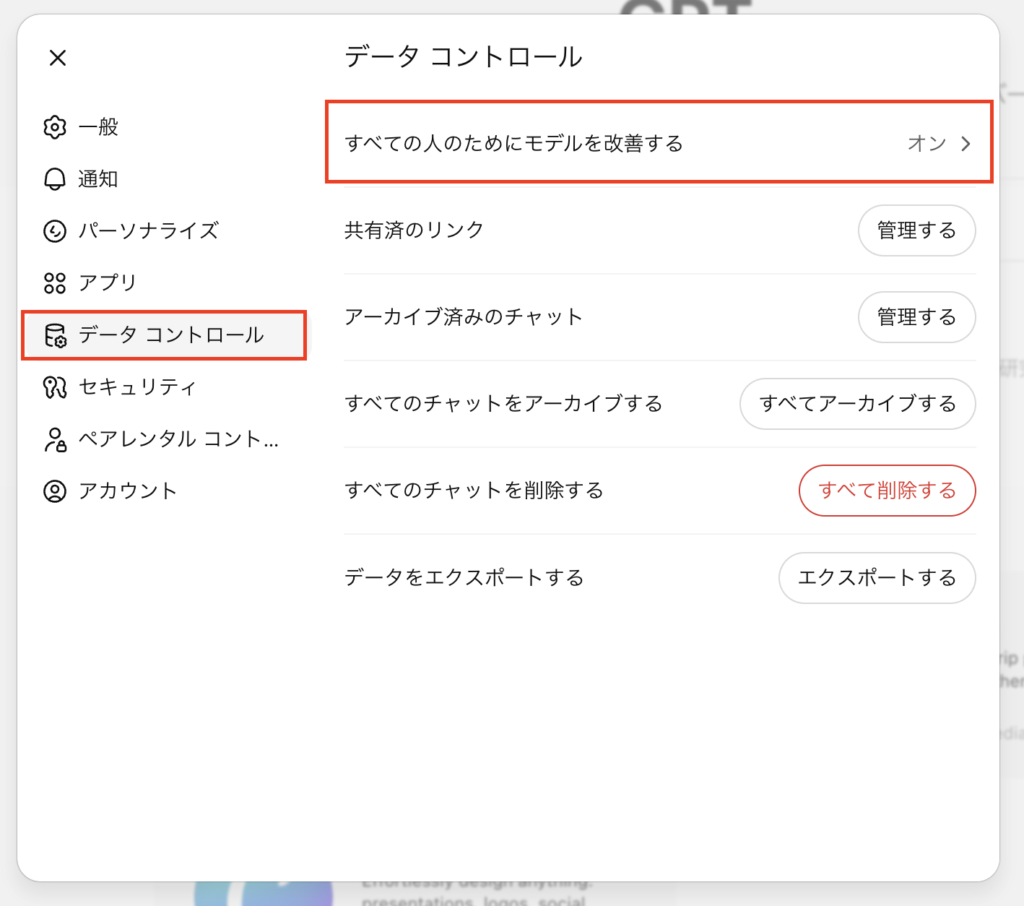
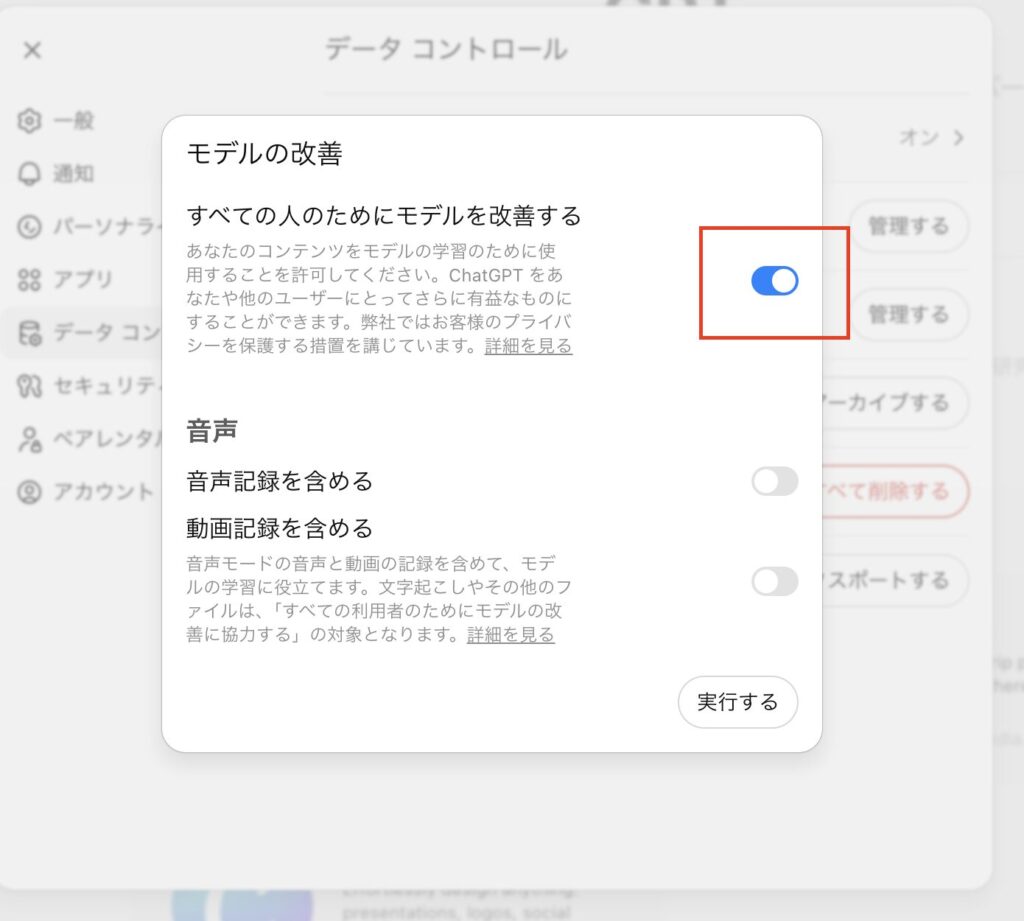
ただし、この設定を有効にするとチャット履歴が保存されなくなるため、過去のやり取りを見返せなくなる不便さがある点には注意が必要です。
3. ChatGPT TeamプランおよびEnterpriseプランのセキュリティ仕様
企業で安全にChatGPTを導入する場合の有力な選択肢が、OpenAIが公式提供する法人向けプラン「ChatGPT Team」「ChatGPT Enterprise」です。
法人プラン最大のメリットは、契約上の規約で「入力データや社内ファイルがOpenAIのモデル学習に利用されることは一切ない」と明言されている点にあります。
管理者向けダッシュボードが提供されており、誰がどのアカウントを使っているかの管理やセキュリティポリシーの一括適用も可能。情報漏洩リスクを根本から排除したセキュアな環境を構築できます。
4. Azure OpenAI Service活用でさらに強固な情報管理を実現
金融機関や医療機関など、さらに厳格なコンプライアンス要件が求められる企業におすすめなのが、Microsoftが提供する「Azure OpenAI Service」です。
Microsoftの堅牢なクラウド環境(Azure)内でChatGPTのモデルを利用でき、データは自社のクラウド契約環境に完全に隔離されます。 OpenAI側にデータが送信されることは一切ありません。
既存の社内データベースやネットワークとの閉域網接続(インターネットを経由しない通信)も容易に実現でき、エンタープライズレベルのアクセス制御・ログ監視機能を備えた最高レベルのセキュリティを確保できます。
5. 社内ガイドライン策定の必須項目チェックリスト
安全なAI活用には、システム導入だけでなく従業員向けの「社内ガイドライン」整備が不可欠です。
ガイドラインに盛り込むべき必須項目は、①入力禁止情報の明確化(顧客の個人情報や営業秘密など)、②利用可能な業務範囲の定義、③生成物の取り扱いルール(AI回答は必ず人間がファクトチェックする義務付け)、④著作権侵害リスクへの配慮(他人の著作物をそのまま入力させないなど)の4点です。
ルールを形骸化させないため、違反時の対応フローまでセットで定めておくことが重要になります。
6. 情報漏洩を防ぐ運用ルールと従業員教育のポイント
情報漏洩を防ぐ最後の砦は、システムを使う従業員自身のITリテラシーです。
ガイドラインを配布して終わりではなく、具体的なセキュリティインシデント事例を取り入れた定期的な社内研修の実施が欠かせません。 AIが生成する回答の限界やプロンプトインジェクションといった新しいリスクを正しく理解させ、AIを「便利な道具」として安全に使いこなせる組織文化を醸成しましょう。
株式会社デジタルゴリラでは、セキュアな環境構築から実効性のあるガイドライン策定、従業員向け研修の実施まで、安全なAI導入をトータルで支援しています。
ChatGPTに社内データを学習させた企業の導入事例7選【2026年版】

「他社は本当に成果を出せているのか?」――AI導入の社内稟議で必ず問われるこの質問に、2026年は具体的な数字で答えられるようになりました。月間22万時間の業務削減、年間44.8万時間の効率化、自治体での全庁導入。本セクションでは、業界も規模も異なる7組織が、それぞれの環境でどうAIを根付かせたのかを紹介します。取り上げるのは以下の事例です。
- 三菱UFJ銀行
- 三井住友フィナンシャルグループ
- ベネッセホールディングス
- パナソニック コネクト
- サイバーエージェント
- 三井不動産
- 横須賀市・東京都・越前市などの自治体
各社の具体的な成功事例を紹介していきます。
1. 三菱UFJ銀行|OpenAIと戦略提携・約35,000人にChatGPT Enterpriseを展開・月22万時間削減試算
株式会社三菱UFJ銀行は、2025年11月にOpenAIと戦略的パートナーシップ契約を締結。2026年1月以降、全行員約35,000人にChatGPT Enterpriseを順次展開しています。
社内文書の作成や調査対応、顧客対応、分析業務など幅広い領域での効率化・高度化が狙いです。生成AIを110業務に導入した結果、月間22万時間もの業務時間削減効果が見込まれると試算されています。
削減された時間を付加価値の高い顧客提案や企画業務に振り向けることで、金融サービスの質の向上に大きく貢献しています。
※参照元:DXマガジン「三菱UFJ銀行、OpenAIと戦略提携 全行員がChatGPT Enterpriseで業務効率化へ」: 日本経済新聞「三菱UFJ銀行、生成AIで月22万時間の労働削減と試算」:
2. 三井住友フィナンシャルグループ|SMBC-GPTによるクローズド環境活用
株式会社三井住友フィナンシャルグループ(SMBCグループ)は、MicrosoftのAzure OpenAI Serviceを活用し、日本総合研究所・NECとともに自社専用のセキュアなAIアシスタントツール「SMBC-GPT」を構築しました。
金融機関特有の厳格なセキュリティ基準をクリアするため、入力データが外部に一切漏れないSMBCグループ専用のクローズド環境を実現しています。
行内では、過去の取引事例や社内マニュアルをAIと連携し、顧客からの複雑な問い合わせへの回答案作成やコンプライアンス(法令遵守)チェックの一次対応に活用。漏洩リスクを物理的に遮断しながら最新テクノロジーを業務の根幹に組み込んでいる模範事例です。
※参照元:三井住友銀行「SMBCグループの専用環境におけるAIアシスタントツール「SMBC-GPT」の実証実験の開始について」:IT Leaders「大規模言語モデルを活用した社員専用AIアシスタント「SMBC-GPT」」
3. ベネッセホールディングス|Azure OpenAI Service活用の「BenesseGPT」をグループ1.5万人へ提供
教育・介護事業を展開する株式会社ベネッセホールディングスは、グループ全従業員約1.5万人向けに、MicrosoftのAzure OpenAI Serviceを活用した社内専用AIチャットツール「BenesseGPT」を開発・提供しています。
Azure上の独自システムで運用されており、機密情報を安全に取り扱える仕様に設計されました。
企画書のアイデア出し、大量のアンケート結果の要約、会議の議事録作成など幅広い業務に活用されており、業務スピードアップだけでなく従業員のクリエイティビティを高めるツールとして根付いています。
※参照元:ベネッセホールディングス「社内AIチャット『Benesse GPT』をグループ社員1.5万人向けに提供開始」
4. パナソニック コネクト|ConnectAIで2024年度に年間44.8万時間削減を実現
パナソニック コネクト株式会社は、全社員が安全に利用できる自社専用AIアシスタント「ConnectAI」を導入し、劇的な業務改革を実現しました。
OpenAI・Google・Anthropicの主要3社のLLMを活用して開発されており、国内の全社員約11,600人向けに2023年2月から導入されています。
2024年度には年間44.8万時間(前年比2.4倍)の業務時間削減を達成。 企画前のリサーチが3時間から5分に、自由記述式アンケート1,500件の分析が9時間から6分に短縮されるなど、驚異的な成果が報告されています。
全社でログを分析し、より効果的な使い方を継続的に啓蒙することで、AI活用が社内の当たり前の風景として定着しています。
※参照元:パナソニック コネクト「ConnectAI 2024年活用実績発表」
5. サイバーエージェント|AIオペレーション室で2026年までに既存業務6割削減を目標
株式会社サイバーエージェントは、2023年10月にAIオペレーション室を新設し、社内データを活用した業務効率化を強力に推進しています。
広告運用やクリエイティブ制作といった主力業務領域において、AIに過去の運用データや制作ノウハウを学ばせることで、2026年までに既存業務の6割削減という極めて高い目標を掲げています。
単純作業の自動化にとどまらず、効果予測や改善提案までAIが担うことで、従業員はより付加価値の高い企画に集中できる環境が整えられています。
※参照元:サイバーエージェント「生成AIで業務効率化を強化、『AIオペレーション室』を新設」
6. 三井不動産|ChatGPT Enterprise全社導入・150名のAI推進リーダー体制で活用拡大
三井不動産株式会社は、2023年8月より生成AIを活用した自社特化型AIチャットツール「&Chat(アンドチャット)」を全従業員約2,500人規模で運用開始しました。
さらに2025年10月1日からはChatGPT Enterpriseを全従業員約2,000人に導入し、生成AIを安全かつ迅速に活用できる環境を整備しています。
全部門から選抜した約150名の「AI推進リーダー」を組織化し、現場起点で独自のAIプロダクト開発・運用を推進。社長AIエージェントなど複数のカスタムAIプロダクトを展開し、業務削減時間10%以上の達成を目標に取り組んでいます。
※参照元:SBビジネスIT「三井不動産150名のAI推進リーダー体制で生成AI活用拡大へ」三井不動産「自社特化型AIチャットツール『&Chat』の運用開始」
7. 横須賀市・東京都・越前市|自治体での社内データ活用事例
神奈川県横須賀市は、2023年4月に日本の自治体として初めて生成AI(ChatGPT)を全庁的に導入しました。
行政ガイドラインや過去の議事データをAIに参照させることで、条文作成や要約業務の大幅な効率化を実現。 東京都でもAIチャットボットを全面導入し、都民からの問い合わせ対応や企画立案の補助に活用しています。
福井県越前市ではローカルLLM(オフラインで動作する大規模言語モデル)を活用し、インターネットに接続せず外部にデータを出さない完全クローズド環境で、機密性の高い行政文書の処理を行っています。
※参照元:総務省「自治体におけるAI活用・導入ガイドブック」:横須賀市「RAGを活用した生成AIツールの実証実験を開始しました」:NTTオープンイノベーション「横須賀市が1カ月で生成AIを全庁導入できた理由」:
ChatGPTの社内データ学習、自社に最適な方法の選び方【5つの判断軸】
手法の比較表を眺めても、なぜか自社の答えが出てこない――そんなときは、判断の「切り口」が足りていないことが多いものです。AI導入の意思決定では、たった1つの基準で選ぶと必ずどこかにしわ寄せが生じます。本セクションでは、選定時に外せない5つの軸を切り口ごとに解説します。
1. 目的別:問い合わせ対応ならRAG、文書作成支援ならファインチューニング
AI導入の目的によって、最適な学習手法は大きく変わります。
社内ヘルプデスクや顧客からの問い合わせ対応を自動化したいなら、社内マニュアルやFAQを参照して正確に回答できる「RAG(検索拡張生成)」が圧倒的に最適です。常に最新情報を検索して回答するため、情報の正確性が求められる業務に向いています。
一方、自社特有のトーン&マナーに合わせたブログ記事の作成支援や、独自プログラミングルールでのコード生成を行いたい場合は「ファインチューニング」が適しています。解決したい課題を明確にすることが、手法選定の第一歩です。
2. データ量別:数百ファイルならGPTs、数万件ならRAG
AIに活用させたいデータの規模も、手法を選ぶ重要な基準です。
部門単位で使う業務マニュアルや、数十〜数百ファイルレベルの小規模データなら「GPTs(カスタムGPT)」の活用が最も手軽。ファイルを画面からアップロードするだけで専用AIが構築できます。
全社で保有する数万件規模の文書ファイルや、日々更新される大規模な社内データベースを丸ごと活用したい場合は、外部データベースと連携する本格的な「RAG」システムの構築が必須となります。データ量が増えるほど、高度な検索の仕組みが重要になります。
3. 予算別:無料〜数万円/月〜数百万円規模の選択肢
確保できるシステム投資の予算によって、取り得る選択肢は大きく異なります。
最もコストを抑えられるのがプロンプトエンジニアリングやGPTsの活用で、ChatGPT Plusの月額数千円程度のライセンス費用のみでスタート可能です。月額数万〜数十万円の予算があれば、法人向けSaaS型(クラウド提供型)のRAGツールを導入し、手軽にセキュアな環境を構築できます。
さらに数百万円以上の初期投資が可能なら、Azure OpenAI Serviceを利用した自社専用RAGシステムのフルスクラッチ開発や、自社データを使ったファインチューニングなど、高度なカスタマイズが実現します。
4. スキル別:ノーコードで始めるか、エンジニア主導で内製するか
社内のITスキルレベルも重要な判断軸です。
プログラミング知識を持つエンジニアが社内にいない場合は、ノーコード(プログラミング不要)で直感的に操作できるSaaS型のRAGツールや、ChatGPT Teamプランの導入が確実で安全です。
社内にエンジニア組織がある、あるいは信頼できる開発パートナー企業と緊密に連携できる体制があれば、LangChainなどのフレームワークを用いた高度なRAGシステムの自社開発や、オープンソースLLMを用いたローカル環境構築など、自社要件に完全に合わせたシステム内製に挑戦できます。
5. セキュリティレベル別:Team・Enterprise・Azureの使い分け【CTA】
企業にとって最も妥協できないのがセキュリティ要件です。顧客情報や機密データを扱う場合、入力データがAIの学習に利用されない環境が絶対条件となります。
数十人規模のチームなら、手軽に管理機能が使える「ChatGPT Team」が適しています。全社規模で高度なアクセス制御が必要なら「ChatGPT Enterprise」、金融・医療機関のように厳格なデータ保護ポリシーがある場合は「Azure OpenAI Service」での構築が必須です。
株式会社デジタルゴリラでは、貴社のセキュリティ要件・予算・スキルに合わせた最適なAI環境の検討から構築までを支援しています。
ChatGPTで社内データ学習を成功させる6つの導入ステップ
AI導入で苦戦する企業に共通するのは、技術力の問題ではなく「順番を間違える」ことです。データを整える前にツールを選んだり、ガイドラインを作る前に全社展開してしまったり――よくある失敗の多くは、進め方さえ正しければ未然に防げます。
本セクションでは、現場に定着するAIを育てるための6ステップを、実行順に整理しました。
ぜひ参考にしてみてください。
1. STEP1:目的とKPIを明確化する(何時間削減するか)
最初のステップは、AI導入で何の課題を解決したいのかという目的と、達成度を測るKPI(重要業績評価指標)を明確化することです。
「営業の提案書作成時間を半減させる」「社内問い合わせ対応の一次返答を100%自動化する」といった具体的な数値目標を設定します。
目標が明確になることで、AIに読み込ませるべきデータが絞り込まれ、どの程度の回答精度が求められるかも決まってきます。
2. STEP2:学習させる社内データを整理・クレンジングする
AIの回答精度は、読み込ませるデータの質に直結します。そのため、学習させるデータを整理し、不要な情報やノイズを取り除く「データクレンジング」作業が最重要です。
古いマニュアルや重複ファイル、表記ゆれのある文書をそのまま読み込ませると、誤った回答(ハルシネーション)を生む原因となります。
情報を最新状態に更新し、見出しや箇条書きで構造化するなど、AIが理解しやすい形に整える地道な作業が、最終的な活用効果を最大化する最大の鍵です。
3. STEP3:5手法から自社に最適な方法を選定する
データの準備が整ったら、自社に最も適した学習手法を選定します。
プロンプトエンジニアリング、GPTs活用、RAG構築、ファインチューニング、API連携──それぞれに得意領域と必要コストが存在します。正確な情報検索ならRAGが圧倒的に有利ですが、特定の文章スタイルを模倣させたいならファインチューニングが適切です。
前述の「目的」「データ量」「予算」「スキル」「セキュリティ」の5つの判断軸を総合評価し、要件を過不足なく満たす最適なアプローチを決定しましょう。
4. STEP4:小規模PoCで精度とROIを検証する
方針が決まっても、いきなり全社導入するのはリスクが伴います。
まずは特定の部門や業務に範囲を絞り、「PoC(概念実証:新しい仕組みが実現可能か検証すること)」を実施して効果を確認しましょう。
この段階でAIが誤答しやすいパターンの把握や、使いやすいプロンプトのひな形作成を行います。小さく始めて課題を洗い出し、確実な成功モデルを作ることが、その後のスムーズな全社展開につながります。
5. STEP5:社内ガイドラインと運用ルールを整備する
現場展開前に必須なのが、安全な利用のための社内ルール策定です。
機密情報や個人情報の入力制限に関するセキュリティ方針、AI生成回答を必ず人間がファクトチェックする運用ガイドラインを整備します。「やってはいけないNG事例」と「業務効率が上がるOK事例」をセットで提示することで、従業員が安心して使える環境が生まれます。
ガイドラインは一度作って終わりではなく、技術進化に合わせて定期的に見直せる運用体制を整えておきましょう。
6. STEP6:全社展開と継続的な精度向上サイクル
検証とルール整備が完了したら、いよいよ全社展開のフェーズです。
導入初期は従業員向けに効果的なプロンプトの作り方や活用事例を共有する社内研修を実施し、利用を促進します。運用開始後は、利用ログの分析や従業員からのフィードバックを定期的に収集し、回答できなかった質問をもとに社内データを追加・修正する継続的なチューニングが欠かせません。
AIは導入して完了ではなく、現場の声を取り入れながら育てていくもの。改善サイクルを回し続けることで、AIはより賢く、手放せない業務パートナーへと成長していきます。
【2026年最新】ChatGPT社内データ活用の最新トレンドと今後の展望
生成AIの世界は、半年前の「常識」が次の半年では通用しないスピードで動いています。モデルの世代交代、エージェント化への大きな潮流、オープンソースの台頭、法人向けプランの機能拡充――2026年に押さえておくべき4つの変化を整理しました。本セクションで扱うのは以下のトレンドです。
- GPT-5.3 / 5.4 / 5.5系モデルへの世代交代
- AIエージェント化の潮流
- オープンソースLLMの活用
- Team・Enterpriseプランの強化
最新トレンドを順に解説します。
1. GPT-5.3 / 5.4 / 5.5系モデルへの世代交代で変わる社内データ活用の精度
社内データ活用の前提となる「AIの賢さ」が、2026年に入ってさらに大きく塗り替えられました。モデル選定の基準も、ここ1年でかなり変わっています。
2026年現在、ChatGPT上の利用可能モデルはGPT-5.3 Instant(全ユーザーのデフォルト)/GPT-5.4 Thinking(推論用)/GPT-5.4 Pro(最上位)の3本柱に整理されています。GPT-4o・GPT-4.1・o3・o4-miniといった旧世代モデルは、2026年2月13日にChatGPTから引退済みです(API経由では引き続き利用可能)。
新世代モデルは、複雑な論理的推論能力や文脈理解力が従来モデルとは比較にならないほど強化されており、込み入った社内規程や専門的な技術文書を読み込ませた際も、矛盾点を正確に指摘したり、複数文書を横断した高度な分析を行ったりすることが可能になりました。
RAGの基盤モデルを最新世代に切り替えるだけで、検索結果の解釈精度や回答の妥当性が一段引き上がるため、すでにRAGを運用中の企業にとっても見直しのタイミングと言えます。
2. AIエージェント化の潮流──「学習」から「自律実行」へ
「AIに聞く」から「AIにやってもらう」へ。2026年最大のパラダイムシフトは、ここに集約されます。質問応答の枠を越えて、業務プロセスそのものをAIに委ねる動きが、いよいよ実用フェーズに入ってきました。
社内データを学習・参照するだけでなく、社内スケジュール管理ツールや経費精算システム、外部Webサービスと直接連携し、「過去の提案書をもとに新しい資料を作成して関係者にメール送信する」といった一連のタスクをAIが自動実行できるようになりました。
「学習」から「自律実行」へ、活用の地平が大きく広がっています。
3. オープンソースLLMでローカル活用という選択肢
クラウド型AIの便利さと引き換えに、データを社外に出すこと自体が許されない業種・業務は厳然として存在します。そうした制約の厚い領域で、ここ1年で急速に存在感を増しているのがオープンソースLLM(無償公開されている大規模言語モデル)の活用です。
Llama 3などに代表される高性能なオープンソースモデルを、外部インターネットと完全遮断したオフライン環境で運用し、社内データを学習させます。
クラウド型AIの利便性を諦めることなく、最高水準の情報管理を実現できる点で、セキュリティ意識の高い企業から支持を集めています。
4. ChatGPT Teamおよびエンタープライズプランの機能強化トレンド
法人向けプランは「契約上データを学習に使わない」という安心材料の提供から、「組織として安全に運用できる管理基盤」へと役割が変わりつつあります。直近のアップデートを見ても、その方向性ははっきりしています。
管理者が従業員の利用状況を細かくモニタリングできる機能や、シングルサインオン(SSO)によるセキュアな認証基盤との統合が標準化されています。
部門ごとに権限を細かく設定し、特定チームだけで機密データを共有できるワークスペース機能も大幅に拡充中。セキュリティとコンプライアンスを確保しながら、大企業でも柔軟かつ迅速にAIを導入・管理できる強固なプラットフォームへと進化し続けています。
ChatGPTの社内データ学習なら株式会社デジタルゴリラへ
自社の貴重なデータを活用し、ChatGPTの真価を安全に引き出すためには、高度な専門知識と豊富な導入実績が欠かせません。
株式会社デジタルゴリラでは、貴社の業務課題に直結する最適なシステム環境の構築から、社内ガイドラインの策定、従業員向け活用研修までをワンストップで伴走支援いたします。
競合他社に差をつける圧倒的な業務効率化を実現したい方は、まずはお気軽に無料相談をご活用ください。生成AIの専門コンサルタントが、貴社の課題に合わせた具体的な導入ロードマップをご提案します。
▼ 無料相談はこちら https://digital-gorilla.co.jp/contact
ChatGPTの社内データ学習に関するよくある7つの質問【2026年最新版】
社内データ活用に関して、企業担当者様から多く寄せられる疑問をQ&A形式でまとめました。本セクションで扱う7つの質問は以下の通りです。
- 無料版での学習可否
- 情報漏洩のリスク
- RAGとファインチューニングの比較
- 費用相場
- 専門知識の必要性
- GPTsとRAGの違い
- モデルの共有リスク
順番に疑問を解消していきましょう。
Q1. 無料版のChatGPTでも社内データを学習させられますか?
無料版のChatGPTに機密性の高い社内データを入力して学習させることは、推奨できません。
無料版では、入力したテキストやデータがOpenAIのAIモデル改善(再学習)に利用される仕様が標準でオンになっています。
設定画面からオプトアウト(学習への利用拒否)することは可能ですが、従業員のヒューマンエラーによる設定漏れリスクが常に伴います。社内情報を安全に扱うには、入力データが学習に利用されないAPI連携や法人向けEnterpriseプランなどの利用が企業としての鉄則です。
Q2. ChatGPTに社内データを入力すると情報漏洩しますか?
利用するプランや設定を誤れば、情報漏洩リスクは確かに存在します。
前述の通り、無料版や個人向け有料版では入力内容がAIの学習データとして利用され、意図せず他社ユーザーへの回答として出力される危険性があります。
一方、「ChatGPT Team」「ChatGPT Enterprise」プランを利用すれば、入力データが再学習に利用されないことが規約で完全に保証されています。
※参照元:wiz LANSCOPEブログ「ChatGPTに学習させない方法とは?画像付きでオプトアウト手順を解説」:https://www.lanscope.jp/endpoint-manager/cloud/column/chatgpt-optout/
Q3. RAGとファインチューニング、結局どちらを選ぶべきですか?
社内規程やマニュアルに基づく「正確な事実の検索と回答」を求めるならRAGを選びましょう。
RAGは外部データベースを都度検索するため、情報更新が容易でハルシネーション(嘘の生成)を抑えやすいのが特長です。
一方、「自社ブランドに合わせた文章スタイル」や「特殊なプログラミングコードの生成」のように、AIの出力スタイルや思考パターン自体を変化させたい場合はファインチューニングを選ぶのがベストです。
Q4. 社内データ学習にかかる費用相場はどれくらいですか?
費用は選択する手法によって大きく変動します。
最も手軽な「GPTs(カスタムGPT)」の利用なら、従業員1人当たり数千円程度のライセンス費用で済みます。
独自のセキュリティ要件に合わせてクラウド上にフルスクラッチでRAGシステムを開発したり、ファインチューニングを実施したりする場合は、初期費用で数百万〜1,000万円以上、さらに長期のクラウドサーバー維持費や保守費用がかかる大規模プロジェクトとなります。
Q5. 専門知識がなくても社内データを学習させられますか?
はい、専門知識がなくても十分にデータを参照・連携させることは可能です。
ChatGPTの標準機能「GPTs」を活用すれば、PDFやテキストファイルを画面上にドラッグ&ドロップするだけで、独自データに基づいたAIアシスタントを直感的に作成できます。
近年は多くの企業から、ノーコードで直感的に操作できる法人向けRAG構築SaaSが提供されています。高度なプログラミングなしでも、マニュアル等のデータ整理さえしっかり実施すれば、現場担当者主導で社内データ連携をスタートできる環境が整っています。
Q6. GPTsとRAGは何が違うのですか?
GPTsはChatGPT画面上で簡単に独自AIを作成できる機能の1つで、アップロードしたファイルを参照して回答する仕組み自体はRAGの一種と言えます。
ただし、ビジネスシステムとして語られる「RAG」は、数万件規模の文書や社内データベースを専用技術(ベクトル化やLangChainなど)で本格的な検索エンジンと連携させた高度なシステムを指します。
GPTsは数十ファイル程度の少量データを手軽に扱うのに適していますが、全社規模の膨大なデータや基幹システムとの連携には、本格的なRAG構築が必要です。
Q7. ファインチューニングしたモデルは他社と共有されますか?
他社と共有されることはありません。
OpenAIのAPIを利用して独自データでファインチューニングを行った場合、作成されたカスタムモデルは貴社アカウント内でのみ専有され、強固に保護されます。
OpenAIの規約でも、ファインチューニング用の学習データや作成された独自モデルが他企業に共有されたり、OpenAIのベースモデル改善に利用されたりしないことが明確に定められています。独自ノウハウが外部に流出する心配はなく、競争力の源泉として安全に維持し続けることができます。
まとめ:ChatGPTに社内データを学習させて、2026年の業務変革を加速させよう
ChatGPTに社内データを連携させることは、もはや一部の先進企業だけの取り組みではなく、すべての企業が取り組むべき急務となっています。
RAGやGPTsといった適切な手法を選び、セキュリティ対策を講じることで、膨大な社内資料の検索や問い合わせ対応の時間を大幅に削減できます。自社の目的・予算・スキル・セキュリティ要件を踏まえて最適な一手を選べば、業務変革は一気に加速するはずです。
「自社に合った具体的な導入手順が知りたい」「セキュリティを確保した独自のRAGシステムを構築したい」というご要望がございましたら、ぜひ株式会社デジタルゴリラの無料相談をご利用ください。生成AIの専門コンサルタントが、貴社の業務変革を力強くサポートいたします。




